Rosario 3D
My developer blog
Triangle render order optimization
Posted by on 19 June 2011
If our render queue is fully optimized and do the minimum state changes on the driver we still can do some optimization?
Think about it, the most frequent task for a 3d engine is to render meshes. So let’s optimize meshes rendering. There is nothing you can do on your code, once you called glDrawElement you are done. But you can optimize the mesh in a way that will be processed faster by our graphic processor.
First, almost every graphic card have a vertex cache, second the triangles are fetched from the buffer in the order you send them.
So if you have a mesh with the following triangle indexes:
0 1 2
1 3 0
4 2 5
the first vertex processed will be the 0, then the 1, then 2 and then again the 1.
Cause the internal cache if the vertex is still there the graphic card will not call the vertex shader again but will reuse the output stored in the cache.
So trying to maximize the cache hit is a good strategy to speed up the program if your application is vertex bounded.
There are different paper about this topic:
Optimization of mesh locality for transparent vertex caching by Hoppe use different aproach the first grow a triangle strip in counter-clockwise order, and for each triangle added check the cache impact and decide if to continue with the strip or to restart with a more cache friendly triangle. If you grow the triangle strip to infinite you always have a vertex out of the cache. The second algorithm more complex and more slow, but produce best cache hit.
Fast Triangle Reordering for Vertex Locality and Reduce Overdraw by Pedro V. Sander, Diego Nehab, Joshua Barczak. Use the Hoppe aproach but subdivide the polygon in “island” with the same normal and then sort the island with the similar normal front to back. In this way the impact on the cache is similar to the Hoppe algorithm but also the overdraw is reduced.
I will use the algorithm described by Tom Forsyth, Linear-Speed Vertex Cache Optimisation, because is fast, is easy to implement and to understand and it’s cache size independent.
You can find the code here: http://www.rsdn.ru/forum/src/3076506.1.aspx
I cleaned the code and removed the boost dependency. Ok, let’s start.
First of all we need to assign the vertexes and the triangle a score, each vertex have higher score if is already in the cache and if have few triangle attached. The triangle score is determinated by the sum of the vertexes score.
The only input is an array of integer that represent list of vertex indexes. We will fill two arrays, one with triangles and another for vertexes information.
The triangle structure will contain the vertex index used, the triangle score and a flag that say if the triangle is already been visited. The vertex structure will contain the vertex score, the list of triangle connected and the current position in the cache.
unsigned int polyCount = indexes_.size() / 3;
unsigned int bestTri = -1;
vector<TriangleCacheData> triangleCache(polyCount);
vector<VertexCacheData> vertexInfo(getVertexNumber());
for(size_t triIndex = 0; triIndex < polyCount; ++triIndex){
size_t base = triIndex * 3;
triangleCache[triIndex].indexes_[0] = unpackedIndexes_[base];
triangleCache[triIndex].indexes_[1] = unpackedIndexes_[base+1];
triangleCache[triIndex].indexes_[2] = unpackedIndexes_[base+2];
triangleCache[triIndex].added_ = false;
vertexInfo[indexes_._[base ]].activeTriangle_.push_back(triIndex);
vertexInfo[indexes_._[base+1]].activeTriangle_.push_back(triIndex);
vertexInfo[indexes_._[base+2]].activeTriangle_.push_back(triIndex);
}
Then we compute the vertex score and reset the cache position, then we compute the triangle score and select the triangle with the higher score (that will be the one with less neighborhood).
for(vector<VertexCacheData>::iterator vIt = vertexInfo.begin(); vIt != vertexInfo.end(); ++vIt)
vIt->score_ = findVertexScore(*vIt);
short max_score = -1;
for(unsigned int triIndex = 0; triIndex < polyCount; ++triIndex){
int score = triangleCache[triIndex].updateScore(vertexInfo);
if(score > max_score ){
max_score = score;
bestTri = triIndex;
}
}
Then until we had visited all triangles we put the selected triangle back to the original array, but in the optimized order and we mark the triangle as visited. Then we removed the triangle from the vertexes (these vertexes will have an higher score in the future) and then update the cache. I implemented the cache with a simple list, I preferred simplicity against performance, the original implementation used a boost circular buffer, use whatever you want, remember that there are a lot of erase in the middle and a lot of push back and push front. Doing performance test the push back didn’t take a lot of time.
unsigned int trisLeft = polyCount;
unsigned int triIndex = 0;
std::list<IndexType> vCache;
while(trisLeft--){
TriangleCacheData& tri = triangleCache[bestTri];
indexes_[triIndex ] = tri.indexes_[0];
indexes_[triIndex+1] = tri.indexes_[1];
indexes_[triIndex+2] = tri.indexes_[2];
triIndex += 3;
tri.added_ = true;
/// reduce valence of used vertexes
for(IndexType const * idx = tri.indexes_; idx != tri.indexes_ + 3; ++idx ){
VertexCacheData & vert = vertexInfo[*idx];
vert.activeTriangle_.erase( std::find(vert.activeTriangle_.begin(), vert.activeTriangle_.end(), bestTri ) );
std::list<IndexType>::iterator inCache = std::find(vCache.begin(), vCache.end(), *idx);
if(inCache != vCache.end())// remove from cache, reput them at the beginning
vCache.erase(inCache);
}
vCache.push_back(tri.indexes_[0]);
vCache.push_back(tri.indexes_[1]);
vCache.push_back(tri.indexes_[2]);
while( vCache.size() > vertexCacheSize)
vCache.pop_front();
Then we need to update the vertex position to update the vertex score.
unsigned int cachePos = vCache.size() - 1;
for(std::list<IndexType>::iterator cIt = vCache.begin(); cIt != vCache.end(); ++cIt){
vertexInfo[*cIt].cachePos_ = cachePos--;
vertexInfo[*cIt].score_ = findVertexScore(vertexInfo[*cIt]);
}
Now for each vertex in the cache, recompute the triangle score.
int max_score = -1;
for(std::list<IndexType>::iterator cIt = vCache.begin(); cIt != vCache.end(); ++cIt){
VertexCacheData & vert = vertexInfo[*cIt];
for( std::vector<unsigned int>::iterator itri = vert.activeTriangle_.begin(),
tris_end = vert.activeTriangle_.end();
itri != tris_end; ++itri){
assert(!triangleCache[*itri].added_);
int score = triangleCache[*itri].updateScore(vertexInfo);
if(score > max_score ){
max_score = score;
bestTri = *itri;
}
}
}
Now this is linear, we compute some vertex score based if the vertex is a good candidate for cache, but there are cases where the algorithm reach a dead end i.e. it’s traversing the mesh that represent an horse and at the end of the food it can’t find any suitable triangle for the cache. In this case the algorithm must restart from another place, so we need to compute the another best triangle from scratch considering only the non visited triangle. Like that
if( max_score == -1 ){
for(unsigned int triIndex = 0; triIndex < polyCount; ++triIndex){
if(!triangleCache[triIndex].added_ && triangleCache[triIndex].score_ > max_score){
max_score = triangleCache[triIndex].score_;
bestTri = triIndex;
}
}
}
My performance test show that this is the most costly part of the code, probably cause I have a lot of restart in my mesh and every time I have to check all the triangles.
Note that you don’t need to run the algorithm every time you load the mesh, but you can precompute the optimized order in your exporter.
Now you only need the score function, in the original article there are a lot of float computation and float comparison, this is bad for the CPU that have different ALU for float and int, like almost every CPU (playstation is really sensible in this topic), the code I found use to table for the score.
int VertexArranger::findVertexScore(const VertexCacheData &vertexData){
static int cacheScoreTable[vertexCacheSize] = {
750, 750, 750, 1000, 949, 898, 849, 800, 753, 706, 661, 616, 573, 530, 489, 449, 410, 372, 335, 300, 266, 234, 202, 173, 145, 119, 94, 72, 51, 33, 18, 6 };
static int valenceBoostScoreTable[16] = {
2000, 1414, 1155, 1000, 894, 816, 756, 707, 667, 632, 603, 577, 555, 535, 516, 500};
if(vertexData.activeTriangle_.size() == 0 )
return -1;
int score = 0.0f;
int cachePosition = vertexData.cachePos_;
if(cachePosition >= 0){
assert(cachePosition < vertexCacheSize);
score = cacheScoreTable[cachePosition];
}
score += valenceBoostScoreTable[std::min(vertexData.activeTriangle_.size() -1,
sizeof(valenceBoostScoreTable)/sizeof(valenceBoostScoreTable[0])-1)];
return score;
}
First note the cacheScoreTable, the first three score are the same, the number is the same cause we want the same result if you insert 0 1 2 or 2 0 1. Also the first three value are lower then the other one to discourage the immediate reuse of the same edge. valenceBoostScoreTable is used to give a large bonus to vertex with few connection, otherwise the algorithm can leave single triangle surrounded by used triangle. These triangles will be selected only at the end, cause they can appear random will have an huge impact on the cache, the boost score greatly alleviate this problem.
The only thing left is the function that compute the triangle score, that it’s trivial, simply sum the triangle vertex score.
inline int VertexArranger::TriangleCacheData::updateScore(const vector<VertexCacheData>& vcd)
{
return score_ = vcd[indexes_[0]].score_ + vcd[indexes_[1]].score_ + vcd[indexes_[2]].score_;
}
Final note
The algorithm is O(numTriangle * cacheSize) the cache size don’t have to be the exact size of the cache, with higher cacheSize you will only increase the computation time but the algorithm will always select the best triangle. The article say that 32 is a good cache size.
Xlib + openGL programming and multithreading
Posted by on 24 January 2011
When programming using Xlib or Win32 the usual program is something like that:
setupWindow()
setupOpenGL()
while(exit)
{
while(haveEvent()){
event = GetEvent()
processMessage(event)
}
applicationLogic()
renderScene()
}
Where in the processMessage() will manage the event like key pressed or mouse moved and applicationLogic() update the application state (like physics simulation). This pattern have two disadvantages
- both the processMessage() and applicationLogic() function can be slow and freeze the rendering (for example when a press return I want to load a picture).
- every frame check in polling if there are some messages, nobody like polling.
Developing a framework the problem is quite common cause you don’t know what the user will do with your framework, the only thing you know is that you don’t want to freeze the rendering.
To make the long story short, we have to move the renderScene() function in another thread. It look incredible but I didn’t found any tutorial about this, so here it is.
I want to create an application that create n openGl windows, each window will have it’s own thread.
Something like this:
for(i = 0; i < numWindow; ++i){
win = setupWindow()
createRenderThread()
}
while(ended)
{
event = waitForEvent() // this thread sleep if there aren't event
processMessage(event)
}
I tried exactly what I wrote above but I got a lot of multi thread issue. If you use multiple context openGl it’s ok with multithreading, is you use the magic function XInitThread also xlib is thread safe, the problem in GLX. It look like that have a bug that freeze the swapbuffer calls when another thread is waiting for events, when they both try to get the display they freeze. I tried different solution (using xcb works on some platform), but the most reliable is to use multiple X connection.
Ok, enought talk, let’s start with the code. I suppose that you already know some basic Xlib programming, so I wont explain basic function call.
First of all we need a structure to contain the shared memory between the main thread and the render thread.
struct RenderData {
Display d_; // Display connection used for this thread
Atom delMgs_; // Explain later
GLXDrawable surface_;
GLXContext ctx_;
// Other data
Color bg_; // background color
Size winSize_; // Windows dimension
};
then we need to initialize the main x connection.
int main(){
// We must call this to make X "thread safe"
XInitThread();
// opening the connection with X
Display *display = XOpenDisplay();
if(display == NULL) return -1; // Add meaning full message error here
int xScreen = XDefaultScreen(display);
// Let's choose a visual (pretty standard function, link to the full code below)
GLXFBConfig *fbConfig = chooseFBConfig(display, screen);
XVisualInfo* visInfo = glXGetVisualInfoFromFBConfig(display, fbConfig[0]);
Window root = XRootWindow(display, screen);
....
Now we must create an Atom to get informed about window destruction (when the user press the X button).
Atom delMsg = XInternAtom(display, "WM_DELETE_MESSAGE", True); ...
Now we can create the windows:
RenderData param[numWindow];
for(int i = 0; i < numWindow; ++i){
// create a X connection for each window
param[i].d_ = XOpenDisplay(NULL);
param[i].delMsg_ = delMsg;
XSetWindowAttributes winAttrib;
// Need to create a color map for each connection
winAttrib.colormap = XCreateColormap(param[i].d_, root, visInfo->Visual, AllocNone);
// Create the window and the openGl context in the standard way
param[i].surface_ = XCreateWindow(param[i].d_, root, 0, 0, 300, 200, 0, visInfo->depth, InputOutput, visInfo->visual, CWColormap, &winAttrib);
param[i].ctx_ = glXCreateContext(param[i].d_, visInfo, NULL, True);
// Now the trick, tell X that we want to retrieve event for the window in the main connection
XSelectInput(display, param[i].surface_, StructureNotifyMask);
// Register the Atom for this window
XSetWMProtocolos(param[i].d_, param[i].surface_, &delMsg, 1);
// Create a new thread (c++0x way)
param[i].thread_ = new thread(render, param+i);
// Keep track of the association window <-> data
wMap.insert(std::make_pair(param[i].surface_, r));
}
The thread function will create a thread that will execute the function render using param+i as parameter.
The render function will simply cycle endlessly until someone press the X button.
void render(RenderData *data){
XEvent event;
// show the window
XMapWindow(data->d_, data->surface_);
// Each thread must have it's current context
glXMakeCurrent(data->d_, data->surface_, data->ctx_);
glClearColor(data->bg.red_, data->bg.green_, data->bg.blue_, 1.f);
while(1){
if(XPending(data->d_){
XNextEvent(data->d_, &event);
// Got death message
if(event.type == ClientMessage && event.xclient.data.l[0] == data->delMsg)
break;
}
glViewport(0, 0, data->winSize_.w, data->winSize_.h_);
// do some rendering here
// Show our beautiful rendering
glXSwapBuffers(data->d_, data->ctx_);
usleep(16000);
}
// Work finished, destroy the context, the window
glXDestroyContext(data->d_, data->ctx_);
XDestroyWindow(data->d_, data->surface_);
// and close the connection
XCloseDisplay(data->d_);
}
The render function render the scene and pool for the close even. In this way we are sure that our render will not freeze.
We need the last part of the code, the event handling. After the for that create the windows…
int windowLeft = numWindow;
while(windowLeft > 0){
RenderData *data;
XEvent event;
XNextEvent(display, &event); // blocking function
switch(event.type){
case ConfigureNotify: // window changed size or position
// get the data associate to the window
data = selectData(wMap, event.xconfigurerequest.window);
data->winSize.w = event.xconfigurerequest.width;
data->winSize.h = event.xconfigurerequest.height;
break;
case DestroyNotify: // the window has been destroyed
data = selectDatta(wMap, event.xdestroywindow.window);
// wait the thread to end
data->thread_.join();
// delete the thread
delete(data->thread);
// remove the thread from the data
wmap.erase(event.xdestroywindow.window);
windowLeft--;
break;
}
}
The StructureNotify we have request to the XSelectInput give us these message: ConfigureNotify, when the window change size or position; DestroyNotify, when the window is destroyed; and other message like Map/Unmap that we are not using.
In this code there is a possible data corruption issue caused by writing in a non atomic way the window size.
Here what you are waiting for, the whole source of the example.
#include <X11/X.h>
#include <X11/Xlib.h>
#include <GL/glx.h>
#include <GL/gl.h>
#include <thread>
#include <map>
using namespace std;
GLXFBConfig *chooseFbConfig(Display *d, int screen);
static const int totalThread = 3;
struct Size{
Size() {}
Size(unsigned int x, unsigned int y):w(x), h(y){}
unsigned int w, h;
};
struct Color{
Color(){}
Color(unsigned int c):
red((0xFF&c)/255.f),
green((0xFF&(c>>8))/255.f),
blue((0xFF&(c>>16))/255.f)
{ }
Color(float r, float g, float b): red(r), green(g), blue(b) {}
float red, green, blue;
};
struct RenderData{
RenderData() : exit(false), thread_(NULL) {}
Display *d_;
Atom delMsg;
GLXContext ctx;
GLXDrawable win;
Color bg;
Size winSize;
bool exit;
thread *thread_;
};
typedef std::map<Window, RenderData*> WinDataMap;
RenderData* selectData(WinDataMap& map, const Window& w){
WinDataMap::iterator it = map.find(w);
if(it == map.end())
throw runtime_error("invalid window");
return (it->second);
}
void render(const RenderData *data)
{
XMapWindow(data->d_, data->win);
glXMakeCurrent(data->d_, data->win, data->ctx);
glClearColor(data->bg.red, data->bg.green, data->bg.blue, 1.0);
while(!data->exit)
{
XEvent event;
if(XPending(data->d_)){
XNextEvent(data->d_, &event);
if(event.type == ClientMessage && static_cast<unsigned int>(event.xclient.data.l[0]) == data->delMsg){
puts("got dead event.. ._.");
break;
}
}
glViewport(0, 0, data->winSize.w, data->winSize.h);
glClear(GL_COLOR_BUFFER_BIT);
glBegin(GL_QUADS);
glVertex2d(0.0f, 0.0f);
glVertex2d(1.0f, 0.0f);
glVertex2d(1.0f, 1.0f);
glVertex2d(0.0f, 1.0f);
glEnd();
if(glGetError() != GL_NO_ERROR)
puts("gl error");
glXSwapBuffers(data->d_, data->win);
usleep(16000);
}
glXDestroyContext(data->d_, data->ctx);
XDestroyWindow(data->d_, data->win);
XCloseDisplay(data->d_);
}
const unsigned int colors[totalThread] = {
0x62E200,
0xFF6F00,
0x7C07A9
};
int main(int argc, char *argv[])
{
Display *d;
XInitThreads();
WinDataMap wMap;
RenderData param[totalThread]; // window parameter
d = XOpenDisplay(NULL);
if(d == NULL){
puts("Unable to connect to X");
return 1;
}
int screen = XDefaultScreen(d);
Atom delMsg = XInternAtom(d, "WM_DELETE_WINDOW", True);
XSetWindowAttributes windowAttr;
GLXFBConfig *fbConfigs = chooseFbConfig(d, screen);
XVisualInfo *visInfo = glXGetVisualFromFBConfig(d, fbConfigs[0]);
Window root = XRootWindow(d, screen);
for(int i = 0; i < totalThread; ++i)
{
param[i].d_ = XOpenDisplay(NULL);
param[i].delMsg = delMsg;
param[i].bg = Color(colors[i]);
param[i].winSize = Size(300, 200);
windowAttr.colormap = XCreateColormap(param[i].d_, root, visInfo->visual, AllocNone);
param[i].win = XCreateWindow(param[i].d_, root, 200,200,
300,200, 0, visInfo->depth, InputOutput, visInfo->visual,
CWColormap,
&windowAttr);
param[i].ctx = glXCreateContext(param[i].d_, visInfo, NULL, True);
XSelectInput(d, param[i].win, StructureNotifyMask);
XSetWMProtocols(d, param[i].win, &(delMsg), 1);
printf("win %lu\n", param[i].win);
wMap.insert(std::make_pair(param[i].win, param+i));
param[i].thread_ = new thread(render, param+i);
}
XFree(visInfo);
XFree(fbConfigs);
int windowLeft = totalThread;
while(windowLeft > 0)
{
RenderData *pData;
XEvent event;
XNextEvent(d, &event);
switch(event.type){
// Structure notify
case ConfigureNotify: // size or position change
pData = selectData(wMap, event.xconfigurerequest.window);
printf("configure win %lu: pos [%d, %d], size [%d, %d]\n", event.xconfigurerequest.window,
event.xconfigurerequest.x,
event.xconfigurerequest.y,
event.xconfigurerequest.width,
event.xconfigurerequest.height
);
// Warning this is not thread safe
pData->winSize.w = event.xconfigurerequest.width;
pData->winSize.h = event.xconfigurerequest.height;
break;
case CirculateNotify:
puts("CirculateNotify"); break;
case DestroyNotify:
puts("DestroyNotify");
pData = selectData(wMap, event.xdestroywindow.window);
pData->thread_->join();
delete (pData->thread_);
wMap.erase(event.xdestroywindow.window);
windowLeft--;
break;
case GravityNotify:
puts("GravityNotify"); break;
case ReparentNotify:
puts("ReparentNotify"); break;
case MapNotify:
printf("Map win %lu\n", event.xmap.window);
break;
case UnmapNotify:
printf("UnMap win %lu\n", event.xunmap.window);
break;
// Unhandled message
default:
printf("Type %d\n", event.type);
break;
}
}
XCloseDisplay(d);
return 0;
}
GLXFBConfig* chooseFbConfig(Display *d, int screen) {
int glAttrib[] = {
GLX_DRAWABLE_TYPE , GLX_WINDOW_BIT,
GLX_RENDER_TYPE , GLX_RGBA_BIT,
GLX_RED_SIZE , 1,
GLX_GREEN_SIZE , 1,
GLX_BLUE_SIZE , 1,
GLX_ALPHA_SIZE , 8,
GLX_DEPTH_SIZE , 24,
GLX_DOUBLEBUFFER , True,
None
};
int num;
GLXFBConfig *fbConfigs = glXChooseFBConfig(d, screen, glAttrib, &num);
if(fbConfigs == NULL) throw runtime_error("Unable to find a frame buffer config!");
return fbConfigs;
}
To compile use:
gcc glThread.cpp -std=c++0x -pthread -l stdc++ -l X11 -l GL -o glthread
–enjoy
Who need focus?
Posted by on 22 December 2010
I’m trying to read get data from various devices for my engine, but I didn’t find a good way to read joystick data with Xlib. Then I read about Evdev.
Basically you can read the files called /dev/input/event* to get the data, it read almost everything, mouse, keyboard, tablet, joystick, wheel.. And the good thing is that it fit perfectly with the multi thread event environment I wrote for my engine.
With ioctl you can get some information about the device *name, id, driver version…)
Then you can read the structure input_event from the file.
The cool thigh about evdev is that you are reading the raw data from the device, so you don’t need the focus.
You can check the linux/input.h file to check the data you can read from the input_event structure.
Here some dirt and quick test, the select is used to check more files/device simultaneously.
The code is based on evtest.
#include <linux/input.h>
#include <algorithm>
#include <vector>
#include <iostream>
#include <fcntl.h>
#include <cstring>
struct DeviceHandle{
int file_;
char deviceName_[256];
};
using namespace std;
int main( int argc, char **argv)
{
int nfds = 0;
vector<DeviceHandle> handle;
fd_set readSet;
FD_ZERO(&readSet);
if(argc-1 <= 0){
cerr << "You must specify some file\n";
return EXIT_FAILURE;
}
for(unsigned int i = 1; i < argc; ++i){
int file;
if((file = open(argv[i], O_RDONLY)) >= 0 ){
nfds = std::max(nfds, file);
DeviceHandle dh;
if(ioctl(file, EVIOCGNAME(sizeof(handle[i].deviceName_)), dh.deviceName_) < 0)
strcpy(dh.deviceName_, "Unknow");
dh.file_ = file;
handle.push_back(dh);
FD_SET(file, &readSet);
}else{
cerr << argv[i] << " is not a valid file or permission denied.\n" ;
}
}
if(handle.size() == 0){
cerr << "No valid files\n";
return EXIT_FAILURE;
}
while(1){
struct input_event ev[64];
int ifd = select(nfds, &readSet, NULL, NULL, NULL);
if(ifd < 0){
cerr << "Select fail\n";
return EXIT_FAILURE;
}else {
for(auto it = handle.begin(); it != handle.end(); ++it){
if(FD_ISSET(it->file_, &readSet)){
cout << "Event from: " << it->deviceName_ << std::endl;
int rd = read(it->file_, ev, sizeof(input_event) * 64);
rd /= sizeof(input_event);
for(unsigned int j = 0; j < rd; ++j)
cout << "Time : " << ev[j].time.tv_sec << "." << ev[j].time.tv_usec << " == Type: " << ev[j].type << endl;
}
}
}
for(auto it = handle.begin(); it != handle.end(); ++it)
FD_SET(it->file_, &readSet);
}
for(auto it = handle.begin(); it != handle.end(); ++it)
close(it->file_);
return EXIT_SUCCESS;
}
To compile
gcc evdev.cpp -std=c++0x -lstdc++ -o evdevtest
and then
sudo evdevtest /dev/input/event*
-Enjoy
Transfert successful
Posted by on 17 December 2010
I have moved my blog from my (now dead) server to wordpress.com. I don’t have all the plug-in I have installed on my server but I think I can survive with basic latex support and no syntax highligth for the code.
Now that the site is up I’ll upgrade more frequently.
Slide su aptica e fisica in real time
Posted by on 6 May 2010
Qui potete trovare in allegato le slide su la lezione di giovedì
Qui potete trovate gli esempi e la libreria physX
Questo è un semplice esempio dell’algoritmo di virtual coupling
// VIRTUAL COUPLING
function FF(device, cursore, dt){
var phPos = vector(3);
var t = vector(1); // tempo del grabber
var objPos = cursore.getPosition();
var velocity = cursore.getVelocity();
var force;
static var k = 15; // guadagno
static var d = 0.5; // smorzamento
device.getPosition(&phPos, &t);
var kcomponent = (phPos-objPos)*k;
var dcomponent = d * velocity;
force = kcomponent - dcomponent;
cursore.addForceAbs(force.x, force.y, force.z);
device.ApplyForce(force, t[0]);
return force;
}
Lezione su gli shader, seconda parte [ITA]
Posted by on 5 May 2010
Illuminazione dinamica
Con le tecniche visto fino adesso l’illuminazione era statica invariante dalle condizioni ambientali o di illuminazione. Il primo shader con illuminazione dinamica che vedremo è lo shader di tipo lambertiano. Lambert ha creato un modello di illuminazione dove la luminosità di una superficie dipende solo dal coseno dell’angolo formato tra la normale della superficie e la direzione di provenienza della luce. In questo vertex shader prendiamo la posizione della luce e un colore base.
Da notare che la normale viene letta tramite la variabile gl_Normal, siccome la normale è un vettore di tre elementi non può essere moltiplicata per la model view (che è 4×4), quindi bisogna usare la matrice gl_NormalMatrix.
uniform vec3 lightPos;
uniform vec3 baseColor;
varying vec3 color;
void main(){
// posizione del vertice in eye space
vec3 vPos = (gl_ModelViewMatrix * gl_Vertex).xyz;
// direzione di provenienza della luce
// attenzione, la posizione della luce deve essere passata in eye space
vec3 lDir = normalize(lightPos - vPos);
vec3 n = gl_NormalMatrix * gl_Normal;
// L'intensità dell'illuminazione è data dal coseno tra i due vettori e non può
// assumere valori negativi.
color = baseColor * max(0.0, dot(n, lDir));
gl_Position = ftransform();
}
Il fragment shader non farà altro che scrivere il colore calcolato sul frame buffer.
varying vec3 color;
void main()
{
gl_FragColor = vec4(color, 1.0);
}
Al posto del colore uniforme possiamo usare una texture, lo shader cambia poco (l’impatto visivo cambia molto).
uniform vec3 lightPos;
varying vec2 uvMap;
varying float diff;
void main()
{
vec3 vPos = (gl_ModelViewMatrix * gl_Vertex).xyz;
vec3 lDir = normalize(lightPos - vPos);
vec3 n = gl_NormalMatrix * gl_Normal;
uvMap = gl_MultiTexCoord0.xy;
diff = max(0.0, dot(n, lDir));
gl_Position = ftransform();
}
Anche il fragment shader è simile all’esempio della texture visto nella prima parte, la cosa da notare è che il colore è modulato in base all’illuminazione.
sampler2D diffuse;
varying float diff;
varying vec2 uvMap;
void main(){
vec4 diffMap = texture2D(diffuse, uvMap);
gl_FragColor = vec4(diff* diffMap.xyz, 1.0);
}
Questo modello di illuminazione è molto semplice ma poco realistico, la luce dalla superficie è come se fosse emessa uniformemente in tutte le direzioni. Questo shader si adatta a pochi materiali, principalmente a oggetti non riflettenti (terracotta, intonaco, pietre), in cui per motivi di performance non vengono considerate le micro sfaccettature.
Phong shader
Questo shader aggiunge alla componente diffusiva una componente speculare. Si basa sull’assunzione che la luce verrà riflessa principalmente lungo vettore simmetrico a quello di direzione della luce (usando come asse di simmetria la normale della superficie) e l’intensità andrà diminuendo man mano che ci si scosta da questo vettore. Per calcolare quanto la telecamera è vicina alla luce riflessa possiamo calcolare la bisettrice tra posizione della telecamera e direzione della luce, useremo il coseno tra la bisettrice e la normale come indice di vicinanza tra i due vettori. La luce speculare decade più o meno velocemente in base alla rugosità della superficie, useremo un fattore per regolare il decadimento della specularità.
uniform vec3 lightPos;
uniform float shininess;
varying vec2 uvMap;
varying float lum;
void main(){
// calcolo la componente diffusiva, niente di nuovo
vec3 vPos = (gl_ModelViewMatrix * gl_Vertex).xyz;
vec3 lDir = normalize(lightPos - vPos);
vec3 n = gl_NormalMatrix * gl_Normal;
uvMap = gl_MultiTexCoord0.xy;
float diff = max(0.0, dot(n, lDir));
float specular = 0.0;
// la componente speculare va calcolata solo se la parte diffusiva è maggiore di zero
if(diff > 0.0){
// calcolo la bisettrice
vec3 vHalf = normalize(lDir - vPos);
// coseno tra bisettrice e normale limitato inferiormente a zero (non vogliamo valori negativi)
float nDotH = max(dot(n, vHalf), 0.0);
// applico il decadimento (phong usa una potenza)
specular = pow(nDotH, shininess);
}
// sommo le due componenti
lum = diff + specular;
gl_Position = ftransform();
}
Il fragment shader a parte il cambio di nome di una variabile è uguale al precedente. Il vero problema di questo shader è che tutte le componenti del illuminazione vengono calcolate nel vertex shader. La specularità è fortemente non lineare (c’è un coseno e una potenza) e le interpolazioni lineari causano dei vistosi artefatti.
Per risolvere il problema possiamo spostare i calcoli nel fragment shader e lasciare il vertex shader l’unico compito di passare i parametri da uno stage all’altro. Questo vertex shader non fa altro che passare i parametri (direzione della luce e della telecamera) da vertice a fragment.
uniform vec3 lightPos;
varying vec3 eyeDir;
varying vec3 lightDir;
varying vec3 norm;
varying vec2 uvMap;
void main(){
eyeDir = -(gl_ModelViewMatrix * gl_Vertex).xyz;
lightDir = normalize(lightPos + eyeDir);
norm = gl_NormalMatrix * gl_Normal;
uvMap = gl_MultiTexCoord0.xy;
gl_Position = ftransform();
}
Tutti i calcoli vengono fatti per pixel. Il fragment shader è molti simile al vertex shader precedente, la cosa importante da notare è che i vettori norm, lightDir, eyeDir che sono assunti come normalizzati nel vertex shader devono essere nuovamente normalizzati perché la loro lunghezza potrebbe essere modificata dall’interpolazione tra vertex e fragment.
uniform float shininess;
uniform sampler2D diffuse;
varying vec3 eyeDir;
varying vec3 lightDir;
varying vec3 norm;
varying vec2 uvMap;
void main(){
vec3 diffMap = texture2D(diffuse, uvMap).xyz;
vec3 n = normalize(norm);
vec3 ld = normalize(lightDir);
vec3 ed = normalize(eyeDir);
float diff = max(0.0, dot(n, ld));
float sp = 0.0;
if(diff > 0.0){
// per calcolare la "distanza" dal vettore riflesso si calcola proprio il vettore
// usando la funzione reflect
vec3 R = reflect(-ld, n);
float nDotH = max(dot(ed, R), 0.0);
sp = pow(nDotH, shininess);
}
gl_FragColor = vec4((diff + sp) * diffMap.xyz, 1.0);
}
Gli oggetti non sono quasi mai speculari uniformemente, usare una mappa per la specularità aumenta notevolmente il realismo dell’oggetto e toglie l’effetto plasticoso tipico dello shader phong.
Potete trovare un ottimo tutorial su come creare empiricamente le specular map a questo link.
uniform float shininess; uniform sampler2D diffuse; uniform sampler2D specular; //... gl_FragColor = vec4(diff *diffMap + sp * specMap, 1.0); }
Normal mapping
Le normal map sono delle texture su cui viene salvata la normale perturbata, cioè il discostamento tra la normale dei poligoni e la vera normale della superficie. Le normal map vengono salvate spesso con riferimento al poligono, quindi tutte le posizioni e direzioni che sono normalmente in eye coordinate devono essere trasformate in quello che viene chiamato tangent space. Per usare il tangent space oltre alla normale bisogna avere una terna ortonormale formata da normale, tangente e binormale. Questa terna viene ricavata dalle normali e le uvMap (se ci sono più uvMap ci possono essere più tangent space per oggetto) e indica lungo quali direzioni sono orientate le normali nella normal map.
La tangente non è un attributo tra quelli predefiniti, dobbiamo usare un nuovo tipo di variabile, il tipo attribute. Un attribute è una variabile che rappresenta un valore associato ad un vertice. Ovviamente anche se semanticamente scorretto potremmo usare uno dei dati non usati (per esempio una texture coordinate) per passare i valori di tangent.
uniform vec3 lightPos;
attribute vec3 tangent;
varying vec3 eyeDir;
varying vec3 lightDir;
varying vec2 uvMap;
void main(){
vec3 n = gl_NormalMatrix * gl_Normal;
// anche tangent è un vettore di 3 ed è solidale alla normale
vec3 t = gl_NormalMatrix * tangent;
// la binormale può essere passata con il suo attribute o può essere ricavata come prodotto vettoriale
vec3 b = cross(n, t);
vec3 v = (gl_ModelViewMatrix * gl_Vertex).xyz;
vec3 temp = -v;
// trasformo la eyeDir in tangent space
eyeDir.x = dot(temp, t);
eyeDir.y = dot(temp, b);
eyeDir.z = dot(temp, n);
temp = normalize(lightPos - v);
// anche la direzione della luce deve essre in tantent space
lightDir.x = dot(temp, t);
lightDir.y = dot(temp, b);
lightDir.z = dot(temp, n);
uvMap = gl_MultiTexCoord0.xy;
gl_Position = ftransform();
}
Notare che il varying per la normale è stato tolto visto che leggeremo la normale dal una texture. A parte questo il fragment shader non cambia molto rispetto all’esempio precedente.
uniform float shininess;
uniform sampler2D diffuse;
uniform sampler2D specular;
uniform sampler2D normal;
varying vec3 eyeDir;
varying vec3 lightDir;
varying vec2 uvMap;
void main(){
vec3 diffMap = texture2D(diffuse, uvMap).xyz;
vec3 specMap = texture2D(specular, uvMap).xyz;
// La texture può memorizzare sono valori positivi, per questo dobbiamo fare
// questo tipo di conversione
vec3 normMap = texture2D(normal, uvMap).xyz * 2.0 - 1.0;
vec3 n = normalize(normMap);
vec3 ld = normalize(lightDir);
vec3 ed = normalize(eyeDir);
float diff = max(0.0, dot(n, ld));
float sp = 0.0;
if(diff > 0.0){
vec3 R = reflect(-ld, n);
float nDotH = max(dot(ed, R), 0.0);
sp = pow(nDotH, shininess);
}
gl_FragColor = vec4(diff *diffMap + sp * specMap, 1.0);
}
Potete trovare un tutorial molto dettagliato che spiega GLSL (in inglese) su questo sito.
Lezione su gli shader, parte prima ITA
Posted by on 4 May 2010
Questo post è in italiano e serve per spiegare la lezione che ho fatto oggi (4 Maggio) al corso di realtà virtuale. Appena ho un po’ di tempo la tradurrò in inglese.
I primi shaders
Tramite vertex shader potete leggere i dati provenienti da openGL manipolarli e inviare altri dati agli stadi successivi della pipeline. Il vertex shader deve scrivere sulla variabile gl_Position, in questo prendo la posizione del vertice (non trasformata) e la invio alla pipeline
void main(){
gl_Position = gl_Vertex;
}
La pileline da i vertici genererà i poligoni che poi verranno renderizzati tramite fragment shader. Il fragment shader deve scrivere su la variabile gl_FragColor
Attenzione!! gl_FragColor e’ stata deprecata in openGL 3.0 e viene sostituita da variabili custom di output. Per ulterio dettagli potete leggere la sezione 3.9.2 delle specifiche openGL (Shader output)
void main(){
gl_FragColor = vec4(1.0, 0.0, 0.0, 1.0);
}
Le trasformazioni possono essere applicate tramite le matrici si puo’ accedere alle matrici tramite le variabile gl_ProjectionMatrix e gl_ModelViewMatrix. Queste due variabili sono invariati per tutti i vertici della geometria, questo tipo di variabili sono dette uniform.
void main(){
gl_Position = gl_ProjectionMatrix * gl_ModelViewMatrix * gl_Vertex;
}
È possibile specificare dei parametri agli shader tramite degli uniform personalizzate. Il nome non può iniziare con gl_, visto che questi nomi sono riservati alle variabili predefinite. In questo caso si e’ passato un colore di riempimento.
uniform vec3 fillColor;
void main(){
gl_FragColor = vec4(fillColor, 1.0);
}
Dal programma che usa lo shader si dovrà specificare il valore dell’uniform, sia il nome che il tipo dovrà corrispondere a quello della variabile
Applichiamo una texture
Per applicare le texture abbiamo bisogno delle coordinate UV, coordinate che possiamo prendere dalla variabile gl_MultiTexCoord0 (si possono usare fino a 8 texture coordinate)
Siccome useremo le UV map nel fragment shader dobbiamo usare una variabile di passaggio. Le variabili di tipo varying permettono di passare i valori i diversi stage della pipeline. Tra vertex shader e fragment i valori verranno
interpolati linearmente.
Attenzione!! Con l’aumentare degli stage della pipeline la keyword varying e’ stata deprecata, ed e’ stata sostituita dalle piu’ esplicite in e out. In questo caso nel vertex shader avremmo una variabile di tipo out e nel fragment una variabile di tipo in.
varying vec2 uvMap;
void main(){
uvMap = gl_MultiTexCoord0.xy;
gl_Position = gl_ProjectionMatrix * gl_ModelViewMatrix * gl_Vertex;
}
La variabile di tipo varying deve essere presente anche nel fragment shader altrimenti la fase di linking genererà un errore. Per leggere la texture bisogna usare un tipo particolare di dato, il sampler2D. Il sampler2D è un intero che può essere usato solo per specificare quale texture usare. In particolare indica quale texture unit usare tra le texture 2D. Ci sono sampler anche per le texture 1D, 3D, cubeMap e altri tipi particolari come per le shadow, nelle versioni più recenti di openGL ci sono ulteriori tipi di sampler per accedere ai moderni textureBuffer e multi sample texture.
Tramite il sampler e le coordinate uv possiamo leggere il valore della texture (texel) usando la funzione texture2D. Di questa funzione esistono diverse varianti, questa è la più semplice che calcola in automatico il livello mipmap da usare.
uniform sampler2D diffuse;
varying vec2 uvMap;
void main(){
gl_FragColor = texture2D(diffuse, uvMap);
}
Possiamo usare due texture e combinarle assieme, nel fragment shader dovremmo dichiarare un’altra variabile varying e leggere un’altra texCoord
varying vec2 uvMap;
varying vec2 uvLightmap;
void main(){
uvMap = gl_MultiTexCoord0.xy;
uvLightmap = gl_MultiTexCoord1.xy;
gl_Position = gl_ProjectionMatrix * gl_ModelViewMatrix * gl_Vertex;
}
Nel fragment shader dobbiamo accedere alle due texture e moltiplicare una per l’altra. Attenzione, la lightmap potrebbe contenere delle informazioni sull’alpha. Se vogliamo usare solo l’alpha delle texture diffusiva dobbiamo separare i calcoli tra colore e alpha.
uniform sampler2D diffuse;
uniform sampler2D lightmap;
varying vec2 uvMap;
varying vec2 uvLightmap;
void main(){
vec4 diff = texture2D(diffuse, uvMap);
vec3 light= texture2D(lightmap, uvLightmap).xyz;
gl_FragColor = vec4(diff.xyz * light , diff.a);
}
Vertex Color
Le informazioni sull’illuminazione posso essere lette anche da vertice. In particolare possiamo leggere il colore per vertice nella variabile gl_Color (e gl_SecondaryColor). Supponiamo di aver memorizzato le informazioni dell’ambient occlusion ne il vertex color.
varying vec4 occlusion;
void main(){
occlusion = gl_Color;
gl_Position = gl_ProjectionMatrix * gl_ModelViewMatrix * gl_Vertex;
}
nel fragment possiamo banalmente copiare il colore per vertice nella variabile di output.
varying vec4 occlusion;
void main(){
gl_FragColor = vec4(occlusion);
}
Questa tecnica si presta bene per mesh molto dense altrimenti si potranno notare artefatti dovuti all’interpolazione tra i vertici.
Un altra cosa che possiamo fare con i vertex shader è animare la mesh, possiamo spostare i vertici a piacimento con la tecnica che preferiamo. Le animazioni tramite bones vengono eseguite nel vertex shader. In questo caso vediamo un animazione procedurale tramite due sinusoidi. Da programma possiamo modificare l’uniform phase per eseguire l’animazione.
uniform float phase;
varying vec4 occlusion;
void main(){
occlusion = gl_Color;
vec4 pos = gl_Vertex;
pos.y = gl_Vertex.y + 0.2*cos(gl_Vertex.y*5.0+phase);
gl_Position = gl_ModelViewProjectionMatrix * pos;
}
Oltre alle variabili gl_ModelViewMatrix e gl_ProjectionMatrix abbiamo a disposizione la matrice gl_ModelViewProjectionMatrix in cui le due sono già moltiplicate a priori.
Nel caso il vertice non debba essere spostato possiamo usare la funzione ftransform() che trasformerà in maniera efficiente e accurata usando le matrici modelview e projection.
Base quaternion math
Posted by on 10 April 2010
Difficult: basic, let’s keep it simple.

A quaternion is a tuple of four number that can be used to represent a rotation. They are composed of number 

The alternatives
You can say, “I already represent rotation with Euler angles and matrix, why I need other maths to do things that I already know?“.
Well, Euler angles are very simple, they only use three numbers but they can give you headaches in some cases, also while summing two rotation is quite simple, rotate a point with Euler angle require expensive trigonometric function, the really bad part about Euler angles is that different combination of angles can give you the same final result and the final result depends on the order in witch you combine the rotation.
Matrix are very generic, a 3×3 matrix can represent rotation, scale and shearing, combining two transformation is more expensive, but rotating a point quite easy. The bad part about rotation matrix is that given a matrix is not easy understand the orientation of the object. Also they use nine numbers, sixteen if you use homogeneous matrices, this can be a problem if you have few memory (for example when you want to pass a lot of parameter to a shader).
Quaternion operation
Quaternion can save you a lot of time, the basic idea is to store a quaternion to represent the orientation of your object and then use them to compute the matrix to send to openGL or if you are using shader you can use quaternion directly.
It can be strange but rotation in 4D are linear, so you can threat quaternion as a simple polynom:
Addition:

Multiplication (to solve the equation remember that 


While adding to quaternion is not meaningful for rotation, the product of two quaternion represent the composed rotation.
We can define the conjugate like this:

Conjugate quaternion represent opposite rotation, rotate a point with a quaternion and then rotate again with his conjugate put back in the place.
The norm is defined like the length of the vector.

Now, we would like to define the inverse operator, so we can derived a rotation that multiplied by another give 1 as result. Let’s try. Remember the norm definition? 


With quaternion compute the inverse is easy as compute a square radix and make a division. Even better is that we will always work with normalized quaternion, so the length will always be one. In this happy case the conjugate is equivalent to the inverse.
Nothing to scare till now, I present only definition, they are quite useless if we didn’t find any practical application, going out with some friend speaking how beautiful quaternion are is pretty lame.
Well as I wrote before, quaternion represent rotation so they can be used to rotate vertexes. If you have a point p and a normalized quaternion 

Using quaternions multiplications the real part became:




While the imaginary part became:

Lagrange’s formula say 

There are the coordinate of the rotated point.
If you want to rotate your object by an 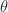

So the axis is related to the imaginary part and the angle represent somewhat the real part, and you can combine multiple quaternion to set complex pose. Now that you have quaternion and we can compose them, you can find useful to convert them to a matrix. Given a quaternion 

Quaternion are very fascinating, but they look quite complex, we really need them? Well the best part of quaternion is that you can interpolate them without to much problem and you get a really smooth orientation change. There are different technique to interpolate quaternion with different result, I’ll show them on another post. Stay tuned.
CppUnit + Hudson = Epic win
Posted by on 28 March 2010
Finally I came with a good test driven pipeline for my code. It’s easy to write a test, I don’t have to write a lot of code for the tests and everything is tested automatically.
CppUnit
CppUnit is a test framework inspired by JUnit, writing test in C++ is more difficult then Java cause C++ don’t have language support to navigate trough classes, but again, a good design can solve a lot of programming issue.
With CppUnit all you have to write to run your test is
int main(int argc, char *argv[])
{
CppUnit::TextUi::TestRunner runner;
CppUnit::TestResultCollector collector;
CppUnit::TestResult result;
result.addListener(&collector);
CppUnit::TestFactoryRegistry ®istry = CppUnit::TestFactoryRegistry::getRegistry();
runner.addTest(registry.makeTest());
runner.run(result);
// writing result on a XML file
std::ofstream xmlFileOut("testresults.xml");
CppUnit::XmlOutputter xmlOut(&collector, xmlFileOut);
xmlOut.write();
return 0;
}
This code create all the structure needed to get all the tests case, collect the results and write everything on a XML file. The file is then analyzed by Hudson.
To create a test case you have to create a class derived by TestFixture and write a methods for each test case. A fixture is a set of test, you can put all your test into one fixture, but is better do subdivide the fixture in different classes for compilation speed and clarity sake. In the test methods you can use some macros to make assertions, if an assertion fail the test fail.
For example here the dot product test to my vector class:
void testDotProduct(){
CPPUNIT_ASSERT(dot(Vec3f::xAxis, Vec3f::yAxis) == 0.0f);
CPPUNIT_ASSERT(dot(Vec3f::xAxis, Vec3f::zAxis) == 0.0f);
CPPUNIT_ASSERT(dot(Vec3f::yAxis, Vec3f::zAxis) == 0.0f);
CPPUNIT_ASSERT_DOUBLES_EQUAL(dot(op1, op1),
op1.length()*op1.length(), tollerance);
CPPUNIT_ASSERT(dot(op1, op2) == dot(op2, op1)); // commutative
CPPUNIT_ASSERT_DOUBLES_EQUAL(dot(7.0f*op1, 5.0f*op2),
(7.0f*5.0f)*dot(op1, op2), tollerance); // distributive
CPPUNIT_ASSERT(dot(op1, op2+op3) == dot(op1, op2) + dot(op1, op3));
}
To help the test runner to collect (and run) all the test the class should declare a static method called suite, it’s a very boring and repetitive method where you have to list all the test. To make it less boring CppUnit have some macros.
CPPUNIT_TEST_SUITE(VecTest); CPPUNIT_TEST(testLinearity); CPPUNIT_TEST(testNormalization); //... CPPUNIT_TEST(testCrossProduct); CPPUNIT_TEST_EXCEPTION(testDivideByZero, MathError); CPPUNIT_TEST(testDotProduct); CPPUNIT_TEST_SUITE_END();
In the main, you should add all the test suite to the runner, another boring work, also you have to include all the file test in the main. This create a lot of dependence, and you have to recompile the main every time you change a test. To avoid these problems you can register your suite into a test factory using the macro
CPPUNIT_TEST_SUITE_REGISTRATION(VecTest);
, and get the test with the factory.
You can find the whole code in the repository. You can find a guide to learn how to use CppUnit here.
Hudson
Hudson is a wonderful tools to automatically compile your code and make a report in case of errors, and also analyze the CppUnit test report (if you install the appropriate plug-in), that’s why I write a XML file in the test case. It’s designed to work with java but I can run any script to compile (so you can invoke make or any other tool chain you use). It can pool for changes in your repository and check if something is changed. But you can also trigger the build process on commit with a simple hook script in your svn repository. Hudson for every commit will check if something is changed in the project and compile if it’s necessary and will also send you a mail if something is wrong. 🙂
I still have to find a good (easy and free) code coverage analyzer, any suggestion?
Earth day
Posted by on 27 March 2010
Today is the earth day, I’ll save some watt turning off the server (no commit today).
See you tomorrow.
